CJKV VBA IME for MS Word
version 3.2
 by WERTA© 2000–2014
by WERTA© 2000–2014
Инструкция для пользователя.
Предлагаемые
макросы предназначены для ввода двухбайтовых символов и текстовой
конверсии как иероглифов, так и различных систем транскрипций для
языков Восточной Азии. Набор включает в себя: китайский, японский,
корейский и вьетнамский модули в формате dot-файлов (шаблоны MS Word).
Системные требования
Для
работы макросов требуется наличие приложения MS Word, уста-новленного
на вашем PC, с версией MS Office не ранее 2000. Данные макросы не имеют
цифровой подписи, поэтому после установки рекомендуется изменить
параметры безопасности вашего MS Word при работе с VBA-макросами
(Сервис => Макрос => Безопасность => Низкая). После запуска MS
Word или после открытия dot-файла появится новая панель инструментов.
Путь работы со вспомогательными файлами таблиц ввода и конверсии
зафиксирован как C:\CJKV_VBA\...
1. Методы ввода MS Word для китайского языка.
1.1 Список IME
Методы ввода (набор символов) для упрощённого китайского:
Фонетические методы (путунхуа)
GuoBiao (JianTi) PinYin
– стандартная пиньинь, с цифровым обозначением тона и буквой
«v» вместо «ü». Набор символов –
GB2312. Упрощённое начертание иероглифов. Раскладка клавиатуры –
стандартная латинская. Режим ввода – ввод одиночного иероглифа
или ввод слов (если тон фонем не был указан цифрой).
Для режимов IME типа PinYin: (GuoBiao (FanTi) PinYin IME, Big5 PinYin IME и PinYin IME (CJK Unified + ExtA)),
предусмотрена возможность переключения вариантов латинизированных
транскрипционных систем ввода. Реализованы 5 дополнительных вариантов
систем транскрипции для ввода фонем стандартного китайского. Активация
посредством циклического нажатия кнопки справа в текстовом поле ввода,
при каждом нажатии цвет кнопки будет изменяться. Системы
латинизированной транскрипции следующие:
• Стандартная Pinyin (серый)
• Wade-Giles Romanization (зеленый)
• MPS II (красный)
• Yale Romanization (желтый)
• TongYong PY (фиолетовый)
• Gwoyeu Romatzyh (синий), после ввода фонемы необходимо нажать пробел и не указывать тон цифрой.
Кроме
стандартной пиньинь, ввод китайских слов для остальных вариантах
перечисленных транскрипционных систем – не реализован.
GuoBiao (JianTi) ShuangPin
– шуанпинь, ввод фонемы происходит всегда в два нажатия. Первое
нажатие соответствует инициали в транскрипции PinYin. Набор символов
– GB2312. Упрощённое начертание иероглифов. Режим ввода
– ввод одиночного иероглифа или ввод слов (если тон фонем не был
указан цифрой).
GuoBiao (JianTi) ZhuYin
– ввод на чжуинь цзыму. Набор символов –GB2312. Упрощённое
начертание иероглифов. Раскладка клавиатуры – стандартная
бопомофо. Режим ввода – ввод одиночного иероглифа.
GuoBiao (FanTi) PinYin
– стандартная пиньинь, с цифровым обозначением тона и буквой
«v» вместо «ü». Набор символов –
GB2312. Традиционное начертание иероглифов. Раскладка клавиатуры
– стандартная латинская. Режим ввода – ввод одиночного
иероглифа или ввод слов (если тон фонем не был указан цифрой).
GuoBiao (FanTi) ShuangPin
– шуанпинь, ввод фонемы происходит всегда в два нажатия. Первое
нажатие соответствует инициали в транскрипции PinYin. Набор символов
– GB2312. Традиционное начертание иероглифов. Режим ввода –
ввод одиночного иероглифа или ввод слов (если тон фонем не был указан
цифрой).
GuoBiao (FanTi) ZhuYin
– ввод на чжуинь цзыму. Набор символов – GB2312.
Традиционное начертание иероглифов. Раскладка клавиатуры –
стандартная бопомофо. Режим ввода – ввод одиночного иероглифа.
Структурные методы
GuoBiao (JianTi) CangJie
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор символов – GB2312. Упрощённое начертание
иероглифов. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части кодирующей строки CangJie. Режим ввода – ввод
одиночного иероглифа.
GuoBiao (JianTi) CangJie (exact)
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор символов – GB2312. Упрощённое начертание
иероглифов. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по полному совпадению символов
введённой части и длины строки кодирующей строки CangJie. Режим ввода
– ввод одиночного иероглифа.
GuoBiao (JianTi) WuBi
– ввод по системе WuBi. Максимальная длина строки ввода равна 4
символам. Набор символов – GB2312. Упрощённое начертание
иероглифов. Раскладка клавиатуры – стандартная WuBi. Режим ввода
– одиночные иероглифы.
Фонетические методы (диалекты)
GuoBiao (JT/FT) Shanghai IME
– ввод иероглифа посредством стандартной латинизированной
транскрипции для шанхайского диалекта, с цифровым обозначением тона
(0-5) Набор символов – GB2312. В списке выбора знака можно
встретить и упрощённое, и традиционное начертания иероглифов. Раскладка
клавиатуры – стандартная латинская. Режим ввода – ввод
одиночного иероглифа.
GuoBiao (JT/FT) Wu IME
– ввод иероглифа посредством обобщённой латинизированной
транскрипции для диалектов группы У, без цифрового обозначения тона.
Набор символов – GB2312. В списке выбора знака можно встретить и
упрощённое, и традиционное начертания иероглифов. Раскладка клавиатуры
– стандартная латинская. Режим ввода – ввод одиночного
иероглифа. Для вывода списка выбора иероглифов после ввода фонемы
необходимо нажать пробел.
Методы ввода (набор символов) для традиционного китайского:
Фонетические методы (мандарин)
Big5 PinYin
– стандартная пиньинь, с цифровым обозначением тона и буквой
«v» вместо «ü». Набор символов –
BIG5. Традиционное начертание иероглифов. Раскладка клавиатуры –
стандартная латинская. Режим ввода – ввод одиночного иероглифа
или ввод слов (если тон фонем не был указан цифрой).
Big5 ShuangPin
– шуанпинь, ввод фонемы происходит всегда в два нажатия. Первое
нажатие соответствует инициали в транскрипции PinYin. Набор символов
– BIG5. Традиционное начертание иероглифов. Режим ввода –
ввод одиночного иероглифа или ввод слов (если тон фонем не был указан
цифрой).
Big5 ZhuYin
– ввод на чжуинь цзыму. Набор символов – BIG5. Традиционное
начертание иероглифов. Раскладка клавиатуры – стандартная
бопомофо. Режим ввода – ввод одиночного иероглифа.
Структурные методы
Big5 CangJie
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор символов – BIG5. Традиционное начертание
иероглифов. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части кодирующей строки CangJie. Режим ввода – ввод
одиночного иероглифа.
Big5 CangJie (exact)
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор символов – BIG5. Традиционное начертание
иероглифов. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по полному совпадению символов
введённой части и длины строки кодирующей строки CangJie. Режим ввода
– ввод одиночного иероглифа.
Big5 Array30
– ввод по системе Array30. Максимальная длина строки ввода равна
4 символам. Набор символов – BIG5. Традиционное начертание
иероглифов. Раскладка клавиатуры – стандартная Array30. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части без учёта совпадения длины кодирующей строки Array30.
Режим ввода – ввод одиночного иероглифа.
Big5 Boshiamy
– ввод по системе Boshiamy. Максимальная длина строки ввода равна
4 символам. Набор символов – BIG5. Традиционное начертание
иероглифов. Раскладка клавиатуры – стандартная Boshiamy. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части без учёта совпадения длины кодирующей строки Boshiamy.
Режим ввода – ввод одиночного иероглифа.
Big5 DaYi(4)
– ввод по системе DaYi. Максимальная длина строки ввода равна 4
символам. Набор символов – BIG5. Традиционное начертание
иероглифов. Раскладка клавиатуры – стандартная DaYi. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части без учёта совпадения длины кодирующей строки DaYi.
Режим ввода – ввод одиночного иероглифа.
Фонетические методы (диалекты)
Big5 Cantonese PY
– кантонская транскрипция, без цифровых обозначений тона. Набор
символов – BIG5. Традиционное начертание иероглифов. Раскладка
клавиатуры – стандартная латинская. Режим ввода – ввод
одиночного иероглифа.
Big5 Hakka PY
– транскрипция для диалектов группы Хакка, с цифровым
обозначением тона (1–6). Набор символов – BIG5.
Традиционное начертание иероглифов. Раскладка клавиатуры –
стандартная латинская. Режим ввода – ввод одиночного иероглифа.
Методы ввода всех иероглифов из расширений UNICODE
PinYin IME (CJK Unified + ExtA)
– стандартная пиньинь, с цифровым обозначением тона и буквой
«v» вместо «ü». Набор иероглифов для ввода
– Unicode: CJK Unified + CJK ExtA. Раскладка клавиатуры –
стандартная латинская. Режим ввода – ввод одиночного иероглифа.
JyutPing IME (CJK Unified + ExtA)
– стандартный ютпхин, с цифровым обозначением тона (1–6).
Набор иероглифов для ввода – Unicode: CJK Unified + CJK ExtA.
Раскладка клавиатуры – стандартная латинская. Режим ввода –
ввод одиночного иероглифа.
CangJie IME (CJK Unified + ExtA)
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор иероглифов для ввода – Unicode: CJK Unified +
CJK ExtA. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части кодирующей строки CangJie. Режим ввода – ввод
одиночного иероглифа.
CangJie IME (CJK Unified + ExtA) exact
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор иероглифов для ввода – Unicode: CJK Unified +
CJK ExtA. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по полному совпадению символов
введённой части и длины строки кодирующей строки CangJie. Режим ввода
– ввод одиночного иероглифа.
CangJie IME (ExtB) –
ввод по системе CangJie. Максимальная длина строки ввода равна 5
символам. Набор иероглифов для ввода – Unicode CJK
ExtB. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по совпадению символов
введённой части кодирующей строки CangJie. Режим ввода – ввод
одиночного иероглифа.
CangJie IME (ExtB) exact
– ввод по системе CangJie. Максимальная длина строки ввода равна
5 символам. Набор иероглифов для ввода – Unicode CJK
ExtB. Раскладка клавиатуры – стандартная CangJie. Отбор
иероглифов в список выбора производится по полному совпадению символов
введённой части и длины строки кодирующей строки CangJie. Режим ввода
– ввод одиночного иероглифа.
1.2 Конверсия текста
Для конверсии достаточно выделить часть текста и нажать кнопку с обозначение нужного вам макроса.
Стандартный китайский
HanZi to PinYin (CJK Unified + ExtA)
– выделенные иероглифы будут преобразованы в текст транскрипции
стандартной пиньинь с цифровым обозначением тона, разделитель –
пробел, например:
[HZ1][HZ2][HZ3] -> pinyin1 pinyin2 pinyin3
Если иероглиф имеет более одного чтения, то его варианты транскрипции будут заключены в круглые скобки, например:
[HZ1][HZ2][HZ3] -> pinyin1 (pinyin2_1, pinyin2_2, pinyin2_3) pinyin3
Иероглифы, доступные для конверсии представлены в Unicode: CJK Unified + CJK ExtA.
Например:
我喜欢电脑游戏
wo3 xi3 huan1 dian4 nao3 you2 (xi4, hu1, hui1)
HZ Colored Tones
– текстовая функция, предназначенная для раскрашивания выделенных
иероглифов в цвет одного из четырёх основных тонов путунхуа,
соответствующего иероглифу. Чёрный цвет соответствует первому тону,
красный – второму, синий – третьему и зелёный –
четвёртому. Серый цвет – это нейтральный тон. Мигающий
розовый цвет означает, что у иероглифа несколько чтений с
различающимися тонами. Фиолетовый цвет означает, что произошло
преобразование третьего тона во второй в соответствии с правилом сандхи
тонов путунхуа.
Например:
我喜欢电脑游戏
我喜欢电脑游戏
1.2.1 Конверсия между различными вариантами пиньинь
PinYin to…, …to PinYin
– Это функции прямого и обратного конвертирования текста между
фонемой со стандартной пиньинь (цифровое обозначение тона) и фонемами с
другими стандартами записи транскрипции. Стандарты транскрипции
представлены следующие:
• Wade-Giles (WD)
• Yale Romanization (YL)
• MPS II (MPS)
• TongYong Pinyin (TY)
• Gwoyeu Romatzyh (GW)
Для
преобразования необходимо выделить фонемы, разделённые пробелом и
нажать соответствующую кнопку, вызывающую выполнение макроса.
Например (PY->Yale Romanization):
wo3 xue2 xi2 zhong1 wen2
wo3 sywe2 syi2 jung1 wen2
PinYin to IPA – преобразует запись фонемы на Пиньинь с цифровым обозначением тона в строку записи символами IPA.
Например:
wo3 xi3 huan1 dian4 nao3 you2 xi4
wuɔ²¹⁴ ɕʅ²¹⁴ huɑn⁵⁵ tiɛn⁵¹ nɑʊ²¹⁴ jɤʊ¹⁵ ɕʅ⁵¹
PY to ZY
– преобразует запись фонемы на пиньинь с цифровым обозначением
тона в эквивалентную строку записи символами алфавита чжуинь цзыму.
Например:
wo3 xi3 huan1 dian4 nao3 you2 xi4
ㄨㄛˇ ㄒㄧˇ ㄏㄨㄢ ㄉㄧㄢˋ ㄋㄠˇ ㄧㄡˊ ㄒㄧˋ
PY
to ZY (fixed) – преобразует запись фонемы на пиньинь с цифровым
обозначением тона в эквивалентную строку записи символами алфавита
чжуинь цзыму cо строго фиксированными позициями четырех знакомест. Т.е.
если, например, медиаль в фонеме нулевая, то вместо неё будет вставлен
для выравнивания азиатский моноширинный пробел. Разделитель фонем
– знак |.
Например:
wo3 xi3 huan1 dian4 nao3
| ㄨㄛˇ|ㄒㄧ ˇ| ㄏㄨㄢ |ㄉㄧㄢˋ| ㄋ ㄠˇ|
PY to RU – преобразует запись фонемы на пиньинь с цифровым
обозначением тона в эквивалентную строку записи системы Палладия с
цифровым обозначением тона.
Например:
wo3 xi3 huan1 dian4 nao3 you2 xi4
во3 си3 хуань1 дянь4 нао3 ю2 си4
PY to PY (tone marks) – преобразует запись фонемы на
пиньинь с цифровым обозначением тона в эквивалентную строку стандартной
Putonghua Pinyin c диакритическим обозначением тона.
Например:
wo3 xi3 huan1 dian4 nao3 you2 xi4
wǒ xǐ huān diàn nǎo yóu xì
PY (tone marks) to PY – преобразует запись фонемы
стандартной Putonghua Pinyin c диакритическим обозначением тона в
эквивалентную строку записи Pinyin c цифровым обозначением тона.
Например:
wǒ xǐ huān diàn nǎo yóu xì
wo3 xi3 huan1 dian4 nao3 you2 xi4
ZY to PY (only one phoneme) – преобразует одну фонему
записи на алфавите чжуинь цзыму в фонему, записанную стандартной
пиньинь с цифровым обозначением тона.
Например:
ㄉㄧㄢˋ =>dian4
Kill Tones – эта функция удаляет любые признаки указания тона в применяемых транскрипциях.
Например:
wo3 xi3 huan1 dian4 nao3 you2 xi4
(или)
wǒ xǐ huān diàn nǎo yóu xì
---------------------------------
wo xi huan dian nao you xi
Кантонский диалект
HanZi to JyutPing (CJK Unified + ExtA) – выделенные в
тексте иероглифы будут преобразованы в транскрипцию ютпхин с
цифровым обозначением тона (1–6), разделитель – пробел,
например:
[HZ1][HZ2][HZ3] -> jyutping1 jyutping2 jyutping3
Если иероглиф имеет более одного чтений, то его варианты транскрипции будут заключены в круглые скобки, например:
[HZ1][HZ2][HZ3] -> jyutping1 (jyutping2_1, jyutping2_2) jyutping3
Иероглифы, доступные для конверсии, представлены в диапазонах Unicode: CJK Unified + CJK ExtA.
Например:
我喜歡電腦游戲
ngo5 hei2 fun1 din6 nou5 jau4 (fu1, hei3)
JyutPing to IPA (GD) – преобразует транскрипцию ютпхин с
цифровым обозначением тона в строку символов IPA (Guandong)
Например:
baak1 ging1 si6 zung1 gwok3 dik1 sau2 dou1
pa:k⁵ kiŋ⁵⁵ si¹¹ tɕʊŋ⁵⁵ kʷɔk³ tik⁵ sɐu²⁵ tou⁵⁵
JyutPing to IPA (HK) – преобразует транскрипцию ютпхин с цифровым обозначением тона в строку символов IPA (H.K.)
Например:
baak1 ging1 si6 zung1 gwok3 dik1 sau2 dou1
pa:k⁵ kiŋ⁵⁵ si¹¹ tsʊŋ⁵⁵ kʷɔk³ tik⁵ sɐu²⁵ tou⁵⁵
JyutPing to RU – преобразует стандартный ютпхин с цифровым
указанием тона в кириллическую практическую транскрипцию для
кантонского диалекта.
Например:
ngo5 hei2 fun1 din6 nou5 jau4 fu1
нго5 хэй2 фунь1 тинь6 ноу5 яу4 фу1
Иероглифические преобразования
FanTi to JianTi (GuoBiao) – преобразует традиционные иероглифы из набора GB2312 в упрощённые иероглифы.
Например:
我喜歡電腦游戲
我喜欢电脑游戏
JianTi to FanTi (GuoBiao) – преобразует упрощённые иероглифы из набора GB2312 в традиционные иероглифы.
Например:
我喜欢电脑游戏
我喜歡電腦游戲
HZ to Radical (CJK Unified + ExtA) – преобразует иероглифы
из диапазонов Unicode: CJK Unified + CJK ExtA, в ключевой знак из
таблицы стандартных 214 иероглифов словаря Кан Си. Принадлежность
иероглифа к ключу определяется в соответствии с его сортировкой в
стандарте Unicode.
Например:
北京是中国的首都
匕亠日丨囗白首邑
HZ to Semantic Variant – функция текстовой конверсии
преобразует иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
семантический вариант.
Например:
簡=>耕
HZ to JianTi Variant – функция текстовой конверсии
преобразует иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
упрощённый вариант начертания.
Например:
簡體漢字=>简体汉字
HZ to SpecSimpl Variant – функция текстовой конверсии
преобразует иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
специальный упрощённый вариант начертания (чаще всего, яп. рякудзи).
Например:
龍=>竜
HZ to FanTi Variant – функция текстовой конверсии
преобразует иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
традиционный вариант начертания.
Например:
简体汉字=>簡體漢字
HZ to Z-Variant – функция текстовой конверсии преобразует
иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
соответствующий Z-вариант начертания.
Например:
繁=>緐
CJK HZ to Compatibility Char – функция текстовой конверсии
преобразует иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
соответствующий вариант совместимости.
Compatibility Char to CJK HZ – функция текстовой конверсии
преобразует иероглиф диапазона вариантов совместимости в
соответствующий иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA.
Преобразования для CangJie
ABC to CJ Code – функция преобразует латинские алфавитные
символы в иероглифические ключевые символы системы CangJie.
Например:
LMP YRF
中一心 卜口火
CJ code to ABC – функция преобразует иероглифические
ключевые символы системы CangJie в латинские алфавитные символы.
Например:
中一心 卜口火
LMP YRF
HZ to CJ Code (ABC) (CJK Unified + ExtA) – функция
преобразует иероглифы из диапазонов Unicode: CJK Unified + CJK ExtA в
латинские алфавитные символы системы CangJie.
Например:
北京=>LMP YRF
Прочее
HanZi to Unicode (Dec) – преобразование иероглифа в
десятичный код символа из набора Unicode. После конверсии разделитель
между полученными числовыми значениями – пробел.
Например:
北京是中国的首都
21271 20140 26159 20013 22269 30340 39318 37117
HanZi to Unicode (Hex) – преобразование иероглифа в
шестнадцатиричный код символа из набора Unicode. После конверсии
разделитель между полученными числовыми значениями – пробел.
Например:
北京是中国的首都
5317 4EAC 662F 4E2D 56FD 7684 9996 90FD
1.3 Модуль CJK-декомпозиции
В качестве базовой основы для описания типов декомпозиции китайского
иероглифа выбран стандарт Ideographic Description Sequence (U+2FF0
– U+2FFB). Однако интерпретация некоторых типов декомпозиции была
изменена в рамках формата строго бинарного подхода в образовании
иероглифа, как сложившегося исторически (ключ + фонетик). В результате,
декомпозиция описывает в составе китайского иероглифа следующие
обязательные компоненты:
• первый знак – ключ (или более сложный знак, содержащий ключ);
• знак декомпозиции;
• второй знак – фонетик или просто второстепенный знак;
• порядок положения ключа (в начале, либо в конце композиции);
• доп. расширенная декомпозиция под первый знак;
• доп. расширенная декомпозиция под второй знак.
Дополнительная расширенная декомпозиция задействуется, если для первого
или второго знака отсутствует символ в наборах стандарта Unicode.
CJK Full Decomposition – функция текстовой конверсии,
разлагающая иероглиф в полную строку декомпозиции. Добавляется знак
”=”.
Например:
愂=((((十⿱冖)⿱子)⿰力)⿱心)
惕=忄⿰(日⿱(勹⿹(丿⿰丿)))
CJK Full Decomposition (rad simpl) – функция текстовой
конверсии, разлагающая иероглиф в полную строку декомпозиции.
Графические варианты ключевых знаков сводятся к основному варианту
ключевого знака. Добавляется знак ”=”.
Например:
惕=心⿰(日⿱(勹⿹(丿⿰丿)))
CJK Full Decomposition (prefix) – функция текстовой
конверсии, разлагающая иероглиф в полную строку декомпозиции в формате
стандартной префиксной IDS записи. Добавляется знак ”=”.
For example:
惕=⿰忄⿱日⿹勹⿰丿丿
CJK Full Decomposition (prefix) (rad simpl)
– функция текстовой конверсии, разлагающая иероглиф в полную
строку декомпозиции в формате стандартной префиксной IDS записи.
Графические варианты ключевых знаков сводятся к основному варианту
ключевого знака. До-бавляется знак ”=”.
Например:
惕=⿰心⿱日⿹勹⿰丿丿
CJK Ideographic Decomposition – функция текстовой
конверсии, разлагающая иероглиф в строку декомпозиции из двух
составляющих компонентов в формате [HZ]=[C1]{decomp}[C2]. Добавляется
знак ”=”.
Например:
湕=氵⿰建
CJK Ideographic Decomposition (rad simpl) – функция
текстовой конверсии, разлагающая иероглиф в строку декомпозиции из двух
составляющих компонентов в формате [HZ]=[C1]{decomp}[C2]. Графические
варианты ключевых знаков сводятся к основному варианту ключевого знака.
Добавляется знак ”=”.
Например:
湕=水⿰建
CJK Ideographic Decomposition (...) – функция текстовой
конверсии, разлагающая иероглиф в строку декомпозиции из двух
составляющих компонентов в формате – ([C1]{decomp}[C2]).
Например:
湕=>(氵⿰建)
CJK Ideographic Decomposition (...) (rad simpl) – функция
текстовой конверсии, разлагающая иероглиф в строку декомпозиции из двух
составляющих компонентов в формате – ([C1]{decomp}[C2]).
Например:
湕=>(水⿰建)
CJK Ideographic Decomposition (prefix)
– функция текстовой конверсии, разлагающая иероглиф в строку
декомпозиции из двух составляющих компонентов в формате префиксной
записи IDS [HZ]={decomp}[C1][C2]. Добавляется знак ”=”.
Например:
湕=⿰氵建
CJK Ideographic Decomposition (prefix) (rad simpl) –
функция текстовой конверсии, разлагающая иероглиф в строку декомпозиции
из двух составляющих компонентов в формате префиксной записи IDS [HZ]={decomp}[C1][C2]. Графические варианты ключевых знаков сводятся к основному варианту ключевого знака. Добавляется знак ”=”.
Например:
湕=⿰水建
CJK Ideographic Decomposition Determinative – функция
текстовой конверсии, возвращающая детерминатив иероглифа (ключевая
часть) из строки декомпозиции.
Например:
湕=>氵
CJK Ideographic Decomposition Determinative (rad simpl) –
функция текстовой конверсии, возвращающая детерминатив иероглифа
(ключевая часть) из строки декомпозиции. Графические варианты ключевых
знаков сводятся к основному варианту ключевого знака.
Например:
湕=>水
CJK Ideographic Decomposition Phonetic – функция текстовой
конверсии, возвращающая неключевую часть иероглифа (фонетик, либо
второй знак в декомпозиции).
Например:
湕=>建
CJK Radical and Strokes Count – функция текстовой
конверсии, отображает ключевую принадлежность иероглифа (по Unicode), а
также полное число строк и число строк добавочного неключевого знака.
Например:
湕=>水(11/9)
CJK Radicals Composition (form) – функция ввода
посредством двухсоставной композиции иероглифа из соответствующей формы
ввода.

1 – поле выбора классических 214 ключей словаря Kang Xi
2 – текстовое поле для ввода английского названия ключа (при
вводе правильного названия, иероглифический ключ в поле 1 будет выбран
автоматически)
3 – для составления композиции берутся только иероглифы из диапазона Unicode CJK Ext A
4 – для составления композиции берутся только иероглифы из диапазона Unicode CJK Unifed Ideographs
5 – выбор иероглифа для композиции из списка, составленного для
выбранного ключевого знака после применения фильтров количества строк
6 – фильтр работает для полного числа строк иероглифа
7 – фильтр работает для числа строк добавочного неключевого знака
8 – задаётся число строк (полных или добавочных) для фильтра отображения иероглифов в элементе 5
9 – задаётся разброс числа строк (полных или добавочных) для фильтра отображения иероглифов в элементе 5
10 – кнопка ввода первого знака из элемента 5 в композицию
11 – кнопка ввода второго знака из элемента 5 в композицию
12 – поле отображении первого знака композиции (двойной щелчок – ввод в текст)
13 – поле отображении второго знака композиции (двойной щелчок – ввод в текст)
14 – поле отображении знака IDS-декомпозиции (двойной щелчок – ввод в текст)
15 – кнопка ввода всей композиции в текст
16 – кнопка ввода знака ”=” в текст
17 – кнопка ввода для ввода результата композиции знаков (активируется, если имеется такой знак в стандарте Unicode)
18 – поле выбора типа композиции знака из набора Unicode
Ideographs Description Sequence (соответствие мнемоник см. в Приложении)
Для ввода ключевых компонентов ⺼“meet” слева или ⻏
“city” справа вам придётся вводить эти символы из
диапазона CJK supplementary radicals (U+2E80–2EF3).
CJK Radicals Composition (3 symbols) – текстовая функция
конвертирует три знака формата [C1]{compos}[C2] в результирующий знак,
если таковой имеется в стандарте Unicode (CJK Unifed + Ext A).
Например:
氵⿰龍
瀧
CJK Radicals Compose Prefix (3 symbols) – текстовая функция конвертирует три знака формата {compos}[C1][C2] в результирующий знак, если таковой имеется в стандарте Unicode (CJK Unifed + Ext A).
Например:
⿰氵龍
瀧
Decomposition Symbol to Mnemonics – знаки декомпозиции в
выделенном тексте преобразуются в соответствующую текстовую мнемонику
(см. Приложение).
Например:
湕=水⿰建
湕=水[LR]建
Delete Decomposition Symbols – знаки декомпозиции в
выделенном тексте заменяются запятыми, а скобки удаляются из строки.
Например:
腍=(⺼⿰((亼⿱乛)⿱心))
腍=⺼,亼,乛,心
Так бывает удобно отображать состав базовых графем в иероглифе.
Decomposition Symbols Count – в выделенном тексте
осуществляется подсчёт числа знаков декомпозиции (U+2FF0 –
U+2FFB) и результат подсчёта заменяет исходную строку выделения.
腍=(⺼⿰((亼⿱乛)⿱心))
腍=3
Это бывает необходимо для отображения логической сложности иероглифа
– полного числа действий композиции при формировании иероглифа из
базовых графем.
1.4 Выбор шрифтов
Font – функция выбора шрифтов для отображения вводимого текста и текстов в формах ввода.
Выбор шрифта для набора символов GB2312
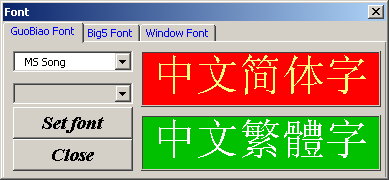
Выбор шрифта для набора символов BIG5
Выбор шрифта для отображения в формах ввода
1.5 Форма ввода
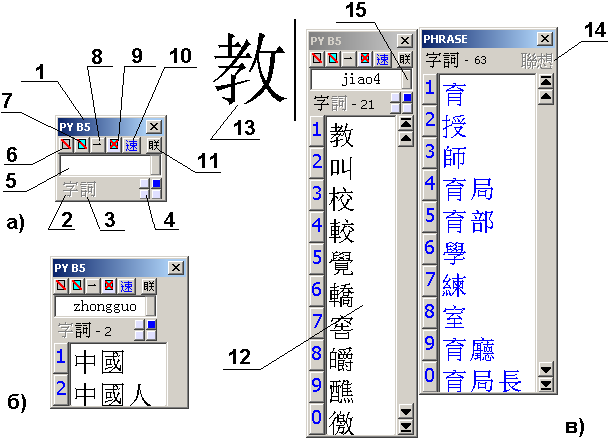
1 – название включенного режима IME
2 – индикатор режима ввода одиночного иероглифа
3 – индикатор режима ввода слов (только для пиньинь) – б)
4 – индикатор положения формы ввода на экране
5 – текстовое окно ввода
6 – сброс списка выбора после закрытия окна связанных слов
7 – закрыть форму выбора связанных слов после вставки в текст
8 – вставлять в текст, если в списке выбора один кандидат
9 – отключить ввод связанных слов
10 – вставлять в текст первый иероглиф из списка выбора
11 – кнопка включения режима Lian Xiang при вводе связанных слов
12 – список выбора иероглифов или слов
13 – иероглиф, введенный в текст документа
14 – индикатор включенного режима Lian Xiang
15 – кнопка переключения вариантов латинизированных систем романизации (только для PinYin IME)
а)– вид панели ввода, в) – ввод связанных слов.
2. Методы ввода MS Word для японского языка
2.1 Список IME
Japanese Romaji – ввод каны посредством использования
транскрипции на латинице. Режим вводимых символов каны переключается на
форме ввода. По умолчанию ввод осуществляется хираганой. Для ввода
закрывающего слог символа ん (-n) нужно дважды нажать N. Сброс
буфера ввода осуществляется через нажатие клавиши Esc. Имеется
возможность активации ввода кандзи из списка выбора.
Japanese Hiragana – ввод каны посредством использования
японской раскладки (хирагана). Режим вводимых символов каны
переключается на форме ввода. По умолчанию ввод осуществляется
хираганой. Сброс буфера ввода осуществляется через нажатие клавиши Esc.
Имеется возможность активации ввода кандзи из списка выбора.
Japanese FourCorner – ввод кандзи по системе 4Corner
(Четыре угла). Максимальная длина строки ввода до 5 символов.
Символы для ввода – (0–9). Дополнительно доступен ввод
символов каны через японскую раскладку клавиатуры. Ввод кандзи из
списка выбора посредством нажатия цифровой клавишей будет доступен
тогда, когда длина введённой строки в кодировке 4Corner равна 5. Если
длина 4Corner-строки в форме ввода менее 5 символов, вы сможете
осуществить ввод из списка выбора посредством нажатия клавишей мыши.
2.2 Конверсия текста
Для конверсии достаточно выделить часть текста и нажать кнопку с обозначение нужного вам макроса.
Hiragana to Romaji (simple) – текстовая функция
преобразует текст хираганы в ромадзи (без учёта соседних знаков в
тексте каны).
Например:
ぼくのせんせいがです
bokunosenseigadesu
Katakana to Hiragana – текстовая функция преобразует катакану в хирагану
Например:
ボクノセンセイガ
ぼくのせんせいが
Hiragana to Katakana – текстовая функция преобразует хирагану в катакану
Например:
ぼくのせんせいが
ボクノセンセイガ
Hiragana to HalfW Katakana – текстовая функция преобразует хирагану в катакану половинной ширины.
Например:
ぼくのせんせいが
ボクノセンセイガ
Kanji to Radical – текстовая функция преобразует кандзи в
ключевой знак из таблицы стандартных 214 иероглифов. Принадлежность
кандзи к ключу определяется в соответствии с его сортировкой в
стандарте Unicode.
Например:
著書南嶋探験
艸曰十山手馬
Kyutaiji to Sintaiji – текстовая функция преобразует
кандзи традиционного начертания в кандзи упрощённого японского
начертания.
Например:
驗=>験
Sintaiji to Kyutaiji – текстовая функция преобразует
кандзи упрощённого японского начертания в кандзи традиционного
начертания.
Например:
験=>驗
Kanji to Unicode (Dec) – текстовая функция преобразует
кандзи в десятичный код символа из набора Unicode. После конверсии
разделитель между полученными числовыми значениями – пробел.
Например:
著書南嶋探験
33879 26360 21335 23947 25506 39443
Kanji to Unicode (Hex) – текстовая функция преобразует
кандзи в шестнадцатиричный код символа из набора Unicode. После
конверсии разделитель между полученными числовыми значениями –
пробел.
Например:
著書南嶋探験
8457 66F8 5357 5D8B 63A2 9A13
2.3 Выбор шрифтов
Font – функция выбора шрифтов для отображения вводимого текста и текстов в формах ввода.
2.4 Форма ввода
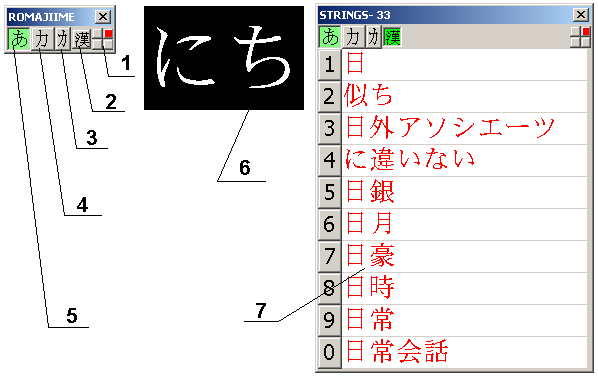
1 – индикатор положения формы ввода на экране
2 – индикатор включения режима ввода одиночных кандзи или слов
3 – индикатор режима ввода половинной катаканы
4 – индикатор режима ввода катаканы
5 – индикатор режима ввода хираганы
6 – вводимый текст
7 – список выбора для кандзи или слов
8 – название метода ввода.
3. Методы ввода MS Word для корейского языка
3.1 Список IME
Hangul (BeolSik) – ввод фонем хангыля по стандартной
корейской раскладке. Сброс буфера ввода осуществляется через нажатие
клавиши Esc. Имеется возможность активации ввода ханча из списка
выбора. Также имеется возможность включения режима ввода простых слов
по первому введённому в текст слогу хангыля. По умолчанию возможен ввод
всех фонем хангыля, включенных в стандарт Unicode. Нажатием
соответствующей кнопки на форме ввода возможно включение режима
KSC-only для фильтрации ввода, при этом будут вводиться только символы
хангыля, входящие в корейский национальный стандарт (KSC).
Hangul (LatinABC) – ввод фонем хангыля по обычной схеме
романизации. Сброс буфера ввода осуществляется через нажатие клавиши
Esc. Имеется возможность активации ввода ханча из списка выбора. Также
имеется возможность включения режима ввода простых слов по первому
введённому в текст слогу хангыля. По умолчанию возможен ввод всех фонем
хангыля, включенных в стандарт Unicode. Нажатием соответствующей кнопки
на форме ввода возможно включение режима KSC-only для фильтрации ввода,
при этом будут вводиться только символы хангыля, входящие в корейский
национальный стандарт (KSC).
3.2 Конверсия текста
Для конверсии достаточно выделить часть текста (кроме функции
тестового вывода символов) и нажать кнопку с обозначение нужного вам
макроса.
Hangul to String – функция текстовой конверсии фонемы
хангыля в строку букв хангыль чамо, из которых состоит эта
фонема.
Например:
곺=>ㄱㅗㅍ
Hangul (Isolated) to New Romanization 2000 – функция
текстовой конверсии фонем хангыля в строку новой корейской романизации,
без учёта взаимного расположения соседних фонем и разбивки на слова в
исходном корейском тексте. После конверсии разделителем текста между
фонемами является пробел.
Например:
한글 자모
han geul ja mo
Hangul (Isolated) to Yale Romanization – функция текстовой
конверсии фонем хангыля в строку Йельской романизации, без учёта
взаимного расположения соседних фонем и разбивки на слова в исходном
корейском тексте. После конверсии разделителем текста между фонемами
является пробел.
Например:
한글 자모
han kul ca mo
Hangul (Isolated) to McCune-Reischauer – функция текстовой
конверсии фонем хангыля в строку романизации по Маккьюну-Райшауэру, без
учёта взаимного расположения соседних фонем и разбивки на слова в
исходном корейском тексте. После конверсии разделителем текста между
фонемами является пробел.
Например:
한글 자모
han kŭl cha mo
Hangul (Isolated) to Joseon Gwahagwon – функция текстовой
конверсии фонем хангыля в строку северокорейской романизации без учёта
взаимного расположения соседних фонем и разбивки на слова в исходном
корейском тексте. После конверсии разделителем текста между фонемами
является пробел.
Например:
한글 자모
han kŭr tsa mo
Hangul (Isolated) to Cyrillization – функция упрощённой
текстовой конверсии фонемы хангыля в строку кириллической транскрипции
(на базе системы Концевича), без учёта взаимного расположения соседних
фонем и разбивки на слова в исходном корейском тексте.
Например:
한글 자모
хан кыль ча мо
Latin IME String to Hangul – функция текстовой конверсии строки типа IME-романизации в фонемы хангыля.
Например:
HAN GEUL JA MO=>한글자모
HAN KEUR CA MO=>한글자모
HAN KEUL CA MO=>한글자모
Все три исходных варианта при конверсии приводят к одной строке, что весьма удобно при романизированном вводе.
Hangul to Latin IME String – функция текстовой конверсии отдельной фонемы хангыля в строку типа IME-романизации.
Например:
한글자모
HAN GEUR JA MO
Type All 11172 Hangul chars – функция тестового вывода
текста из всех фонем хангыля, включенных в стандарт Unicode (выполнение
этой функции займет некоторое время)
Например:
가,각,갂,갃,간,갅,갆,갇,갈… (в столбик)
Hangul to Unicode (Dec) – текстовая функция преобразует
символ хангыля в десятичный код символа из набора Unicode. После
конверсии разделитель между полученными числовыми значениями –
пробел.
Например:
한글 자모
54620 44544 51088 47784
Hangul to Unicode (Hex) – текстовая функция преобразует
символ хангыля в шестнадцатиричный код символа из набора Unicode. После
конверсии разделитель между полученными числовыми значениями –
пробел.
Например:
한글자모
D55C AE00 C790 BAA8
Hanja to Unicode (Dec) – текстовая функция преобразует
ханча в десятичный код символа из набора Unicode. После конверсии
разделитель между полученными числовыми значениями – пробел.
Например:
韓契字母
38867 63753 23376 27597
Hanja to Unicode (Hex) – текстовая функция преобразует
ханча в шестнадцатиричный код символа из набора Unicode. После
конверсии разделитель между полученными числовыми значениями –
пробел.
Например:
韓契字母
97D3 F909 5B50 6BCD
Hanja to Hangul – текстовая функция преобразует ханча из
диапазонов Unicode: CJK Unified + CJK ExtA, в соответствующее ему
чтение на хангыль. Если чтение ханча имеет варианты, то результат
оформляется в круглые скобки с разделителем – запятая.
Например:
韓契字母
한글자모
Hanja to Radical (Unicode) – текстовая функция преобразует
ханча в ключевой знак из таблицы стандартных 214 иероглифов.
Принадлежность ханча к ключу определяется в соответствии с сортировкой
в стандарте Unicode.
Например:
韓契字母
韋大子毋
3.3 Выбор шрифтов
Font – функция выбора шрифтов для отображения вводимого текста и текстов в формах ввода.
3.4 Форма ввода
1 – кнопка включения режима фильтрации фонем KSC-only
2 – кнопка включения режима ввода простых слов
3 – кнопка включения режима ввода ханча
4 – индикатор положения формы ввода на экране
5 – вводимый знак хангыля
6 – список выбора для ханча (или для слов)
4. Методы ввода MS Word для вьетнамского языка
4.1 Список IME
Telex (VISCII) – основа раскладки – стандартная
латинская. Ввод гласных букв вьетнамского языка осуществляется по
системе Telex. Модификаторы тональности гласных это клавиши: F, S, X,
J, R. Модификаторы гласных Â,Ê,Ô –
соответственно двойные нажатия A,E,O. Модификатор для Ư, Ơ –
клавиша W. Модификатор для Đ – двойное нажатие D. Для корректного
отображения символов необходим шрифт однобайтовой кодировки VISCII (к
макросам прилагается шрифт C:\CJKV_VBA\VIETNAMESE\Viet.ttf). Режим
ввода иероглифов недоступен.
VIQR fast (VISCII) – основа раскладки – стандартная
латинская. Ввод гласных букв вьетнамского языка осуществляется по
системе VIQR (быстрый вариант, не более двух нажатий). Для корректного
отображения символов необходим шрифт однобайтовой кодировки VISCII (к
макросам прилагается шрифт C:\CJKV_VBA\VIETNAMESE\Viet.ttf). Режим
ввода иероглифов недоступен.
Telex (Unicode) – основа раскладки – стандартная
латинская. Ввод гласных букв вьетнамского языка осуществляется по
системе Telex. Модификаторы тональности гласных это клавиши: F, S, X,
J, R. Модификаторы гласных Â,Ê,Ô –
соответственно двойные нажатия A,E,O. Модификатор для Ư, Ơ –
клавиша W. Модификатор для Đ – двойное нажатие D. Для корректного
отображения символов необходим любой Unicode шрифт с расширенным
набором символов латиницы. Доступен ввод иероглифов.
VIQR fast (Unicode) – основа раскладки – стандартная
латинская. Ввод гласных букв вьетнамского языка осуществляется по
системе VIQR (быстрый вариант, не более двух нажатий). Для корректного
отображения символов необходим любой Unicode шрифт с расширенным
набором символов латиницы. Доступен ввод иероглифов.
4.2 Конверсия текста
Для конверсии достаточно выделить часть текста (кроме функций
тестового вывода символов) и нажать кнопку с обозначение нужного вам
макроса.
Type VISCII vowels LowCase – тестовый вывод списка букв
для всех вьетнамских гласных во всех вариантах указания тональности.
Строчный регистр букв, кодировка VISCII.
Например:
a à
á ạ
ã ả
â ầ ấ ậ ẫ ẩ
ă ằ ắ ặ ẵ ẳ
e è
é ẹ ẽ
ẻ
ê ề ế ệ ễ ể
o ò
ó ọ
õ ỏ
ô ồ ố ộ ỗ ổ
ơ ờ ớ ợ ỡ ở
u ù
ú ụ ũ
ủ
ư ừ ứ ự ữ ử
i ì
í ị ĩ
ỉ
y ỳ ý ỵ ỹ ỷ
Type VISCII vowels UpCase – тестовый вывод списка букв для
всех вьетнамских гласных во всех вариантах указания тональности.
Заглавный регистр букв, кодировка VISCII.
Например:
A À
Á Ạ
à Ả
 Ầ Ấ Ậ Ẫ Ẩ
Ă Ằ Ắ Ặ Ẵ Ẳ
E È
É Ẹ Ẽ
Ẻ
Ê Ề Ế Ệ Ễ Ể
O Ò
Ó Ọ -
Ỏ
Ô Ồ Ố Ộ Ỗ Ổ
Ơ Ờ Ớ Ợ Ỡ Ở
U Ù
Ú Ụ Ũ
Ủ
Ư Ừ Ứ Ự Ữ Ử
I Ì
Í Ị Ĩ
Ỉ
Y Ỳ Ý - - -
Type Unicode vowels LowCase – тестовый вывод списка букв
для всех вьетнамских гласных во всех вариантах указания тональности.
Строчный регистр букв, кодировка Unicode.
Например:
a à
á ạ
ã ả
â ầ ấ ậ ẫ ẩ
ă ằ ắ ặ ẵ ẳ
e è
é ẹ ẽ
ẻ
ê ề ế ệ ễ ể
o ò
ó ọ
õ ỏ
ô ồ ố ộ ỗ ổ
ơ ờ ớ ợ ỡ ở
u ù
ú ụ ũ
ủ
ư ừ ứ ự ữ ử
i ì
í ị ĩ
ỉ
y ỳ ý ỵ ỹ ỷ
Type Unicode vowels UpCase – тестовый вывод списка букв
для всех вьетнамских гласных во всех вариантах указания тональности.
Заглавный регистр букв, кодировка Unicode.
Например:
A À
Á Ạ
à Ả
 Ầ Ấ Ậ Ẫ Ẩ
Ă Ằ Ắ Ặ Ẵ Ẳ
E È
É Ẹ Ẽ
Ẻ
Ê Ề Ế Ệ Ễ Ể
O Ò
Ó Ọ
Õ Ỏ
Ô Ồ Ố Ộ Ỗ Ổ
Ơ Ờ Ớ Ợ Ỡ Ở
U Ù
Ú Ụ Ũ
Ủ
Ư Ừ Ứ Ự Ữ Ử
I Ì
Í Ị Ĩ
Ỉ
Y Ỳ Ý Ỵ Ỹ Ỷ
VIQR to VISCII – текстовая конверсия строки в форме записи
на VIQR во вьетнамские символы кодировки VISCII. Для корректной работы
нужен шрифт с символами однобайтовой кодировки VISCII.
Например:
Tie^'ng Vie^.t
Tiếng Việt
VIQR to Unicode – текстовая конверсия строки в форме
записи на VIQR во вьетнамские буквы кодировки Unicode. Для корректной
работы необходимо наличие любого шрифта с расширенным набором символов
латиницы в Unicode (Times New Roman).
Например:
Tie^'ng Vie^.t
Tiếng Việt
VISCII to Unicode – текстовая конверсия строки в кодировке VISCII в строку с кодировкой Unicode.
Unicode to VISCII – текстовая конверсия строки в кодировке
Unicode в строку с кодировкой VISCII. Для корректной работы необходимо
наличие шрифта с символами однобайтовой кодировкой VISCII (viet.ttf).
VISCII to VIQR – конверсия строки вьетнамского текста VISCII-кодировки в способ записи VIQR.
Например:
Tiếng Việt
Tie^'ng Vie^.t
Unicode to VIQR – конверсия строки вьетнамского текста Unicode-кодировки в способ записи VIQR.
Например:
Tiếng Việt
Tie^'ng Vie^.t
HanNom to VIET string – текстовая функция преобразует
выделенный иероглиф из диапазонов Unicode: CJK Unified + CJK ExtA, в
соответствующее ему вьетнамское звучание. Если звучание иероглифа имеет
варианты, то результат оформляется в круглые скобки с разделителем
– запятая.
Например:
越南=> việt nam
4.3 Форма ввода
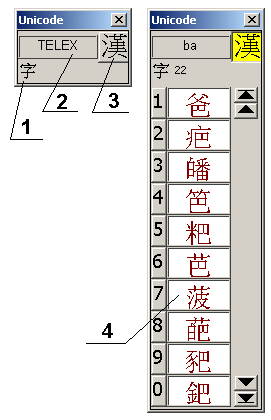
1 – индикатор обозначения числа иероглифов в списке выбора
2 – индикатор метода ввода (или текстовое поле ввода)
3 – кнопка включения режима ввода иероглифов
4 – список выбора иероглифов
5 – кодировка вводимых символов.